컬렉션 프레임웍(collection framework)
1.컬렉션 프레임웍
다수의 데이터를 저장할 수 있는 클래스 - - > 컬렉션 클래스
컬렉션 프레임웍? 다양한 종류의 컬렉션 클래스를 표준화된 방식으로 체계화한 것
컬렉션 프레임웍으로 인해, 다수의 데이터를 다루는 데 필요한
다양하고 풍부한 클래스를 활용할 수 있다.
또한, 인터페이스와 다형성을 이용한 객체지향적 설계에 의해
표준화되어 있기 때문에 편리하다는 장점도 있다.
cf. 라이브러리 vs 프레임웍
라이브러리는 공통적으로 사용될만한 유용한 기능을 모듈화하여 제공,
반면 프레임웍은 기능뿐만 아니라 프로그래밍 방식을 정형화하여 개발 생산성을 높임
1)컬렉션 프레임웍의 핵심 ‘인터페이스’

컬렉션 프레임웍에서는 컬렉션 데이터 그룹을 3가지로 분류
각 컬렉션을 다루는데 필요한 기능을 가진 3개의 인터페이스를 정의
인터페이스 List 와 인터페이스 Set의 공통된 부분을 추출하여 Collection을 추가로 정의
cf. Map인터페이스는 컬렉션 인터페이스의 상속계층도에 포함되지 않는다.
| 인터페이스 | 특징 |
| List | 순서가 있는 데이터의 집합, 중복 허용 |
| 구현 클래스 : ArrayList, LinkedList, Stack | |
| Set | 순서를 유지하지 않는 데이터의 집합, 중복 불가 |
| 구현 클래스 : HashSet,, TreeSet | |
| Map | 키(key)와 값(value)의 쌍으로 이루어진 데이터 집합 순서 유지 않음. 키는 중복 불가, 값은 중복 허용 |
| 구현 클래스 : HashMap, TreeMap, Hashtable |
2) List 인터페이스
List 인터페이스 - 저장 순서 유지, 중복 허용하는 컬렉션을 구현하는데 사용된다.
cf. Vector (Old), ArrayList(New). 둘의 차이점은 동기화. ArrayList는 동기화되지 않았음
① ArrayList
ArrayList 는 List 인터페이스를 구현했기 때문에 저장 순서를 유지하고, 중복을 허용한다.
또한, 배열을 통해 데이터를 저장한다.
우선, 배열의 특징에 대해 확인하자.
배열은 데이터를 읽는 시간이 짧지만, 크기를 변경할 수 없다.
배열의 저장공간이 부족할 때 어떻게 하는 가?
더 큰 배열을 생성 -> 기존 배열을 복사 -> 참조 변경
따라서
ArrayList에 저장된 객체의 삭제
세번째 데이터를 삭제하기 위해 remove(2)를 호출했다고 가정하자.
삭제할 객체의 바로 아래의 있는 데이터를 한 칸씩 위로 복사해
삭제할 객체를 덮는 방식으로 처리.
만약 삭제할 객체가 마지막 데이터라면 복사 없이 단순히 null로 변경하면 완료
ArrayList 예제

ArrayList 메서드
ArrayList() 크기가 0인 ArrayList를 생성
ArrayList(Collection c) 주어진 컬렉션이 저장된 ArrayList를 생성
ArrayList(int initialCapacity) 지정된 초기 용량을 갖는 ArrayList를 생성
boolean add(Object o) ArrayList의 마지막에 객체를 추가. 성공하면 true
void add(int index, Object element) 지정된 인덱스에 객체를 저장
boolean retainAll(Collection c) ArrayList에 저장된 객체 중에서 주어진 컬렉션과 공통된 것들만 남기고 나머지 삭제
boolean contains(Object o) 지정된 객체가 ArrayList에 포함되어 있는지 확인
(반환 타입 boolean -> 변화가 있었을 때 true 반환, 변화 없으면 false 반환)
②Linked List
배열과 달리, 링크드 리스트는 불연속적으로 존재하는 데이터를 연결
링크드리스트는 요소 하나 하나를 연결하는데, 그것을 노드라고 한다.
데이터의 삭제 : 삭제하고자하는 요소의 이전요소가
삭제하고자 하는 요소를 참조하도록 변경. 단 하나의 참조만 변경하면 삭제됌
데이터의 추가 : 새로운 요소를 생성한 다음 추가하고자하는 위치의 이전 요소를
새로운 요소에 대한 참조로 변경하고, 새로운 요소가 그 다음요소를 참조하도록 변경
그러나 단점도 있다.
데이터의 접근성이 나쁘다.
불연속적이기 때문에 첫번째에서 n번째가려면 n-1만큼 이동해야하지, 한번에 갈 수가 없다.
ArrayList vs LinkedList 성능 비교
순차적 추가/삭제 : ArrayList
비순차적 데이터 추가/삭제 : LinkedList
접근시간 테스트 : ArrayList
읽기 : ArrayList
변경: LinkedList, 순차적변경은 ArrayList
비효율적 메모리 사용 -- >> ArrayList
데이터가 많을 수록 접근성 떨어짐 -->>LinkedList
3 )Stack과 Queue
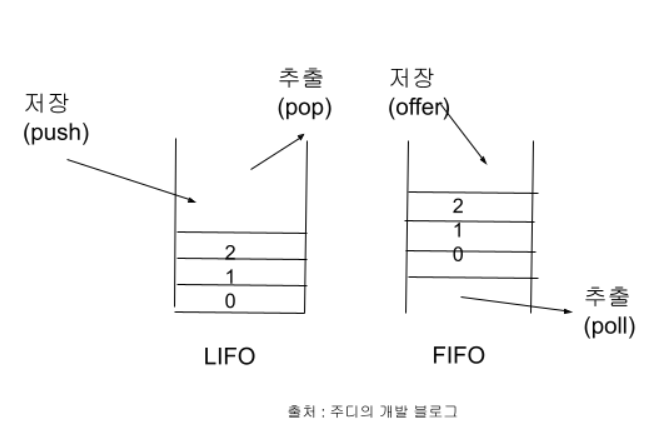
스택 - 마지막에 저장한 데이터를 가장 먼저 꺼내는 Last In First Out 구조
즉, 스택은 바닥이 막혀서 한 방향으로만 뺄 수 있는 구조
큐 - 처음에 저장한 데이터를 가장 먼저 꺼내는 First In First Out 구조
큐는 양 위아래가 뚫려 있어 한 방향으로는 넣고, 한 방향으로는 빼는 구조
따라서 순차적으로 데이터를 추가하고 삭제하는 스택에는
ArrayList 같은 배열기반의 컬렉션 기반 클래스가 적절하다.
큐는 데이터를 꺼낼 때 항상 첫번째 저장된 데이터를 삭제하므로,
데이터의 추가,삭제가 쉬운 LinkedList가 적절하다.
스택과 큐의 활용 예시
스택 - 수식 계산, 수식 괄호 계산 , 웹브라우저 뒤로, 앞으로
큐 - 최근 사용 문서, 인쇄작업 대기 목록,
①큐
자바에서 큐는 인터페이스로 저장되어 있다.
Queue q = new Queue(); 불가// 인터페이스니까 인스턴스 생성 불가.
(cf. stack은 stack 이란 클래스가 있다.)
큐는 인터페이스다.
큐의 기능을 가지고 싶은 객체를 갖고 싶은데 어떻게 해야 할까?
-> 큐를 구현한 클래스를 사용한다.
Java API 에서
Interface Queue<E>
..
All Known Implementing Classes :
큐 인터페이스를 구현한 클래스 목록이 제시되어 있다.
목록중에 LinkedList가 있다.
따라서 Queue q = new LinkedList();와 같이 사용하면 된다.
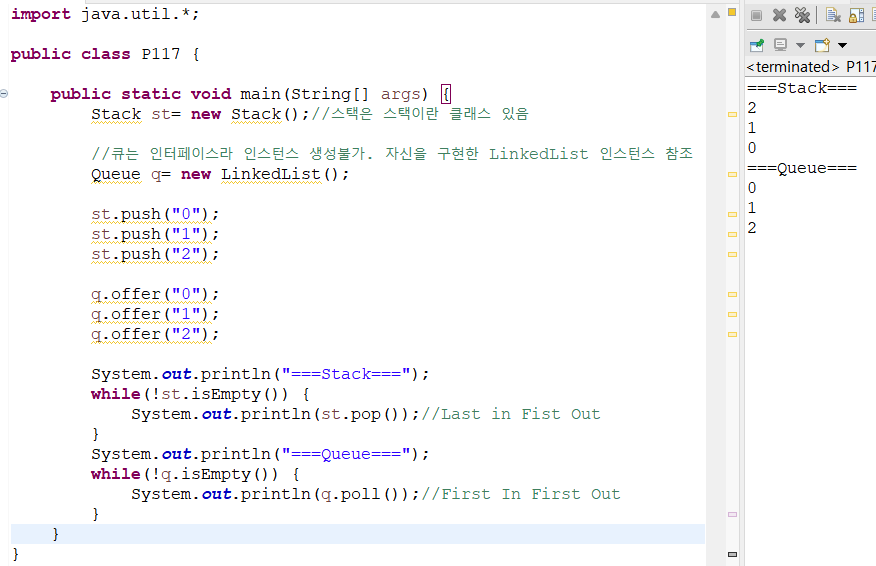

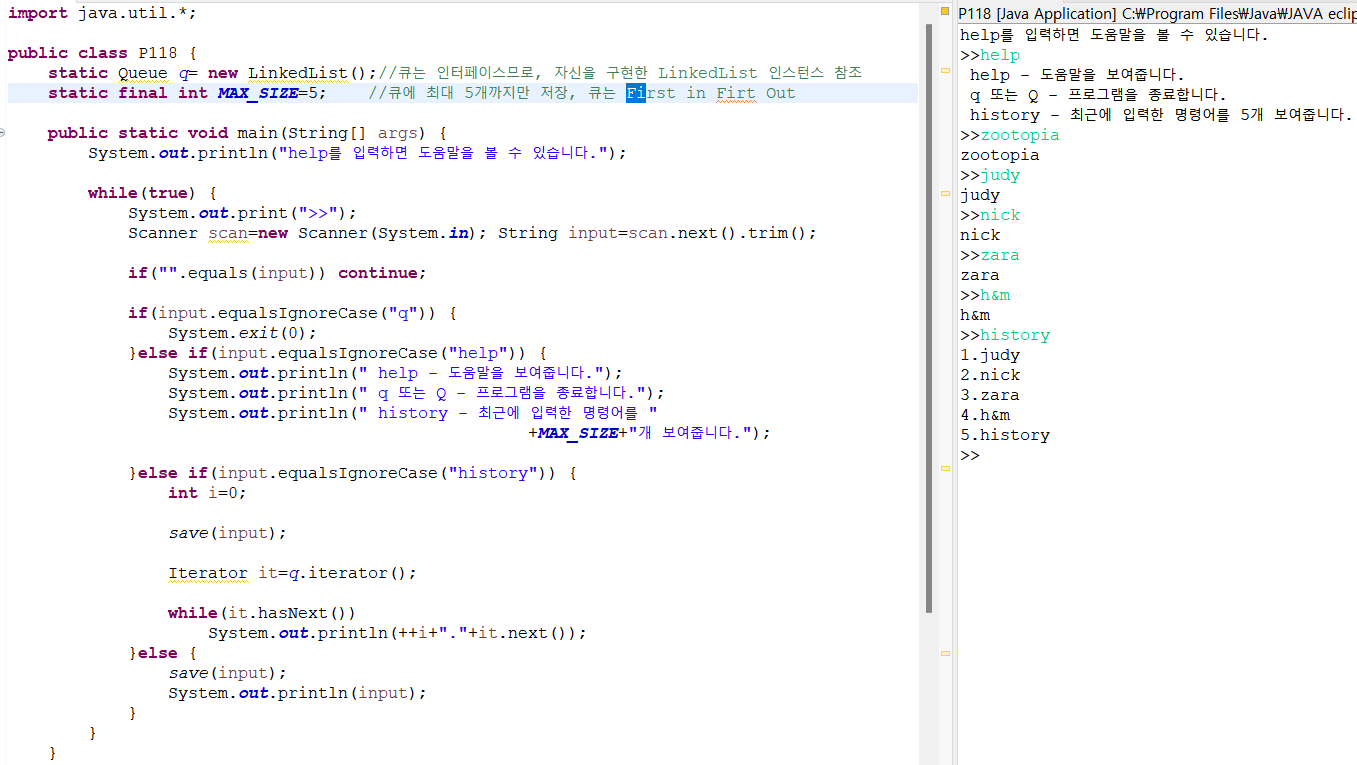

4) Iterator, ListIterator, Enumeration
컬렉션에 저장된 데이터를 읽는 데 사용되는 인터페이스
컬렉션 프레임웍에서는 컬렉션에 저장된 요소들을 읽어오는 방법들을 표준화했다.
Iterator - 컬렉션에 저장된 요소를 접근하는데 사용되는 인터페이스(단방향)
ListIterator - Iterator의 접근성을 향상시킨 것(단방향 -> 양방향)
다음요소, 이전요소 모두 읽어 올 수 있다
Enumeration(Iterator 의 구버전)
Iterator를 어떻게 사용하는 가?
컬렉션에 iterator()를 호출해서 iterator()를 구현한 객체를 얻어서 사용

Iterator는 Collection 인터페이스에 정의되어 있다.
그래서 Collection 의 List, Set 모두 iterator를 가지고 있다.
단, iterator는 일회용이다.
한번 끝까지 다 읽고나면, iterator를 다시 얻어서 작동시켜야 한다.
어떻게 읽을 것인가?
① hasNext() 확인 -> ② next() 읽기
Boolean hasNext() - 읽어 올 요소가 남았는지 확인. 있으면 T, 없으면 F
Object next() - 다음 요소를 읽어 온다.
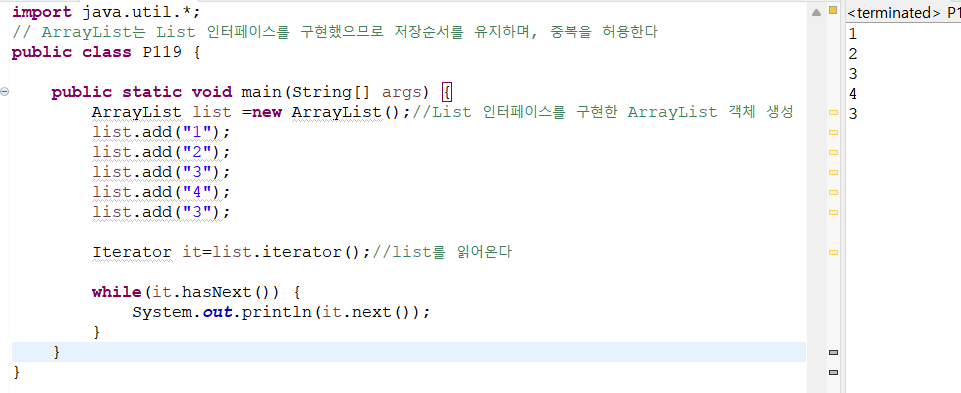
List 클래스들은 저장 순서를 유지하기 때문에
읽어온 결과 역시 저장순서와 동일하다.
반면, Set 클래스들은 순서 유지가 되지 않으므로
읽어온 결과가 저장순서와 일치하지 않는다.
cf. Map과 iterator
Map에는 iterator()가 없다. Map은 컬렉션의 자손이 아니다.
따라서 keySet(), entrySet(), values()를 호출해야 한다
keySet(), entrySet() 은 반환타입이 set이며,
values() 반환타입은 collection이다. 즉 모두 iterator를 가지고 있다.

'Java' 카테고리의 다른 글
| Java 지네릭스, 열거형, 애너테이션 (0) | 2022.04.28 |
|---|---|
| Java 컬렉션프레임웍 - (2) (0) | 2022.04.27 |
| Java 날짜와 시간 & 형식화 (0) | 2022.04.18 |
| java.lang패키지와 유용한 클래스-(1) (0) | 2022.04.15 |
| Java 예외처리 (0) | 2022.04.14 |



